My Top Five Feature Requests


In June I wrote about my top 10 feature requests for the TiDB server. For a quick update: I am pleasantly surprised that my top 3 requests are being worked on. FOREIGN KEYS also look like they will ship by the end of the year, truly impressive work by the TiDB engineering team!
But that feature request list was limited to the tidb server, my primary area of expertise at the time. I have now spent the last 4 months working on productionalizing TiDB as a whole. Which brings us to today's topic, what are my top feature requests across the whole product line?
My Top 5
#5 Make it easier to deploy TiDB. It feels like TiDB suffers from a case of Conway's law, with the core-server team in close collaboration but the tools and deployment systems on the outside.
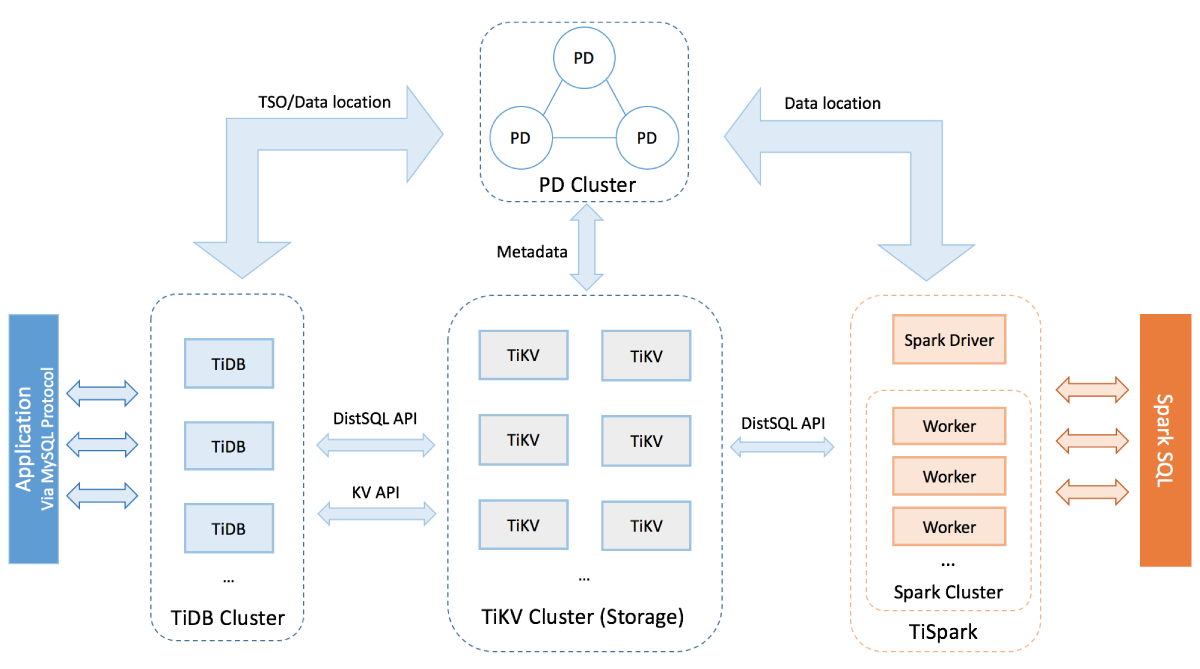
If you come from the MySQL world, you are used to replication being built into the server. In TiDB it's a set of external tools (DM if replicating from MySQL, CDC if replicating between TiDB servers). Setup is aided by TiUP and TiDB-Operator supporting these tools, but the processes to manage differs between them which makes documentation more complex.
As I stated in my earlier post - the TiDB server needs a scheduling framework built into it to perform background tasks such as updating statistics and performing DDL. Why can't this framework handle internal replication tasks as well?
Separating these components could still be supported, but for smaller clusters an all-in-one approach is better because it helps simplify configuration and reduce the minimum footprint.
#4 Consider documentation more in feature development. This somewhat relates to the previous point, but is more specific about developing features in such a way that they are easier to explain. i.e. we've all heard of Test-Driven-Development (TDD), but how about Documentation-Driven-Development (DDD)? If you had to write the docs first, I can think of quite a few scenarios where the final outcome would change.
I previously wrote about how the configuration story has problems. The real issue is that there are two configuration systems in TiDB (system variables and the configuration file). There is no relation between the two, and it is up to the developer which method they chose. Users are confused by this all the time, take this TiDB community slack thread:
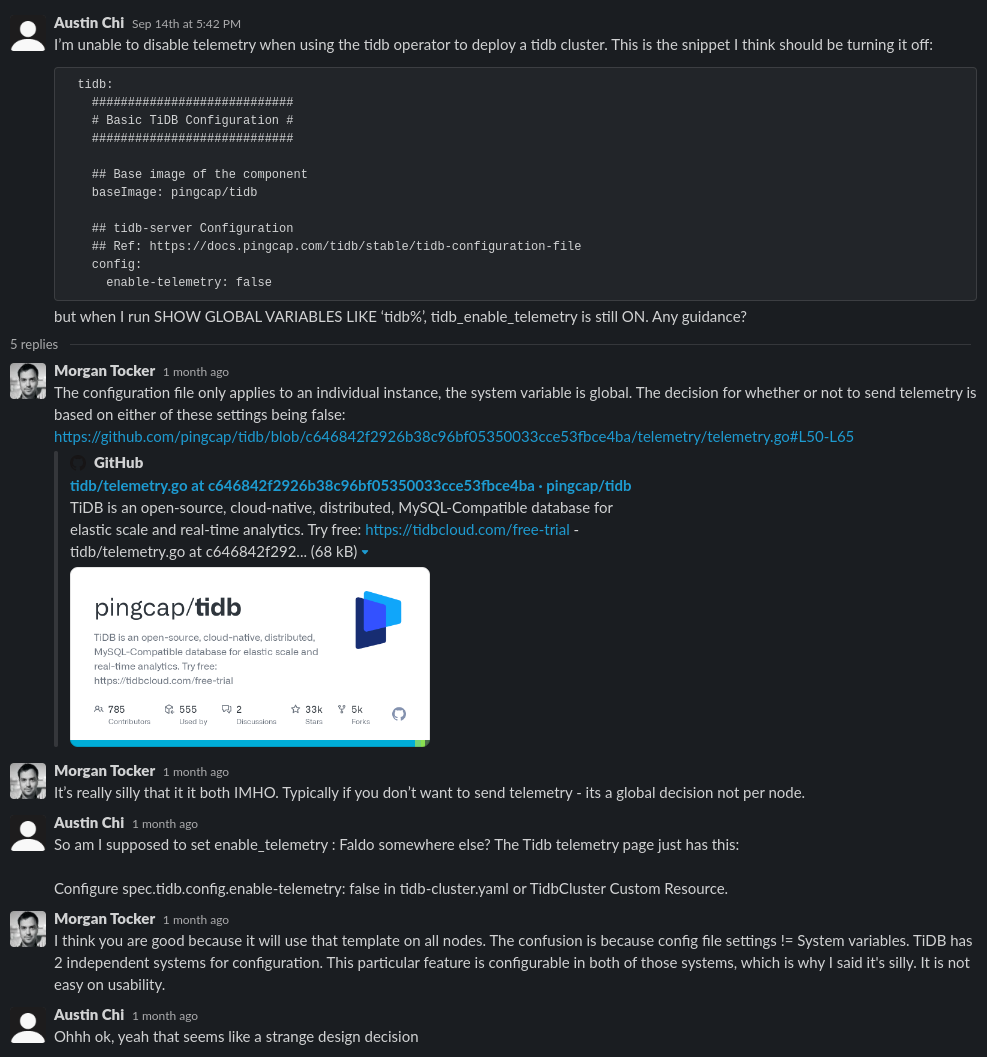
My complaint here is about usability: even if I understand these nuances, I have to plan for a larger team to be able to support TiDB with me. I like to take vacations too, so I would accept a slightly lower new feature velocity in exchange for fewer sharp edges. Considering documentation as part of the development process means:
- Making sure commands are copy-pasteable (for example they don't depend on the output of a previous command).
- Commands work the same across all platforms.
- Clients are installed by default and behave the same everywhere.
- The examples in the documentation are included in CI, so it becomes clear when they break.
- Making sure that FAQs and troubleshooting guides are reviewed with each new release.
- Making sure key documentation (such as system variables defaults, possible values and scope) is always up to date.
Example violations of this:
- Exactly 1 year ago, I reported a bug that the
tiup clientexamples in the manual don't work. It remains unfixed. - A few weeks ago, I found myself working through the Build Multiple Interconnected AWS EKS Clusters guide, and hit several issues where it has clearly not been tested recently.
- In my previous post I also mentioned how the system variable documentation is out of date, and missing documentation for about 50 variables. The actual number was closer to 85! But this has been fixed very recently, so hats off to PingCAP on this one. I still have a few minor gripes where default values are out-of-date, but it is much improved from where it was just a few months ago.
#3 Support HLC. I have had several user-requests to deploy global clusters which (for ease of configuration) are updatable everywhere. With the use of placement rules, it's already possible to move certain tables (or partitions) closer to where they will be accessed by users. However, it's not currently practical to update those tables because two network round trips to a centralized location are required for the TSO.
At the heart of a modern NewSQL database is a dependency on a strict order of operations, which is usually ensured via time. Because atomic clocks are not available in commodity environments yet, there are unfortunate trade-offs which need to be taken instead:
- In the case of TiDB, it uses a central node on the network (the Time-Stamp Oracle; TSO).
- For CockroachDB, it uses an approach which tolerates 500ms (default) clock skew.
The tradeoff with CockroachDB's choice is pretty well explained in the docs: if it encounters a larger clock skew than 500ms it spontaneously shuts down for safety. My feature request is for the benefit of geo-distributing data, TiDB should implement the same tradeoff.
This also has the benefit that it lessens the impact on the PD-server as a bottleneck since it is no longer handing out timestamps to clients. In benchmarking, my colleagues have shown that this is a bottleneck since it can only be scaled vertically.
#2 Lower the minimum cost. The minimum deployment for TiDB is 8 nodes: 2x TiDB, 3x PD, 3x TiKV. TiDB requires 48G+ RAM in production, and TiKV requires 64G+.
Some users deploy with lower specs than this, but because the tidb-server does not have great resource control I typically suggest following the recommendation. To translate this into costs: it is typical to spend $5000/m on a TiDB cluster before it has any DR or CDC capabilities.
Is $5000/m a lot? Certainly not if you operate 3-4 database clusters. But it is typical to build applications with microservices these days, and have each service responsible for its own database. This can translate to 100 database clusters, with staging and production environments. So some quick back-of-napkin math shows this becomes a $1M/m (5000*100*2) floor before you get started.
Because the floor is so high, my experience has been that it leads to service owners either adopting Aurora first (planning to migrate later, which is never fun) or skipping all the pain and just adopting DynamoDB because it has a much lower floor. I have observed the latter is the most common.
This really is a serious issue for TiDB. I have several ideas how the cost could be lowered:
- Embed the pd-server into the tidb-server binary by default. This will make the most sense if TSO allocation stops being a bottleneck (FR #3 above), but it's not a hard-requirement.
Architecturally this change is not perfect because it makes the tidb-server stateful (you can't scale it down quickly), but it's already unsafe to scale down too quickly: open transactions will be terminated, and DDL jobs will need to be rescheduled. Larger installations will want to separate the pd-server to its own component again (and also separate DDL, which is not yet supported).
- Offer native multi-tenancy of PD and TiKV. Most of the resource control issues lie with the tidb-server and not with the pd and tikv-servers. Aurora uses multi-tenancy of the storage between different customers (encrypting the data in 10G chunks). Can we deploy TiKV in the same way?
I can't guarantee this will work for my use-cases, as I have additional requirements that make multi-tenancy difficult. But I can see it working for a lot of users with many smaller databases.
- Offer an S3-backed storage engine. TiKV (and the expensive EBS volumes it requires) make up a significant amount of the cost, which is 3x because of replication. How about instead of having 3 copies, have 1 copy in EBS + a copy in S3? Reads can come directly from the TiKV copy, and writes will have about the same risk of data loss as async replication does (the log is flushed to disk locally on EBS, but writes to S3 are async).
Overall incorporating S3 into TiKV will lower its cost, but I can see some reluctance because it makes the deployment pattern for on-premises installs different.
Low starting cost is important because of the competition: Aurora (and MySQL for that matter) actually scales pretty well. I see no problem with recommending it for up to 5TB databases, and I draw the arbitrary line here largely because schema changes become difficult on large tables.
Having to operate different database technologies for big and small clusters is not what most ops teams want to do, so unfortunately it becomes a bit of a winner-takes-all scenario where a high minimum cost puts TiDB on the losing side.
#1 Improve DR Functionality. Remote DR (Disaster Recovery) support in TiDB is severely lacking. In the beginning the recommendation was to use TiDB-Binlog, but it has since been replaced by TiCDC. I have several issues with TiCDC which make it unusable:
- The throughput is too low. I can exceed the capacity of the TiCDC pipeline using a single threaded batch-insert from one client on one TiDB server.
- It does not respond well to network events (disconnects, etc). When it resumes it needs to read from all regions again, and on moderate sized databases this can be a 30m+ stall before replication starts again. For those with a 10m RTO, this is a deal-breaker.
- There is not much visibility into its delay, such as if the number of pending replication events is increasing or decreasing. There is time, but on a bursty workload that is usually an unreliable metric.
I enquired why TiCDC does not use the same replication pipeline as TiFlash uses (Raft learner). The answer was somewhat puzzling in that TiCDC was not designed with low latency replication in mind (i.e. it was designed to batch feed Kafka).
As an alternative deployment pattern, I also experimented with having one cluster span multiple-regions. While this seems to work, it is not documented well, and increases the minimum cost since it is recommended to run with 5 copies (instead of 3).
My feature request is for: is a raft-learner based DR option. Maybe this is TiCDC based, or maybe TiKV can replicate directly to remote learner peers? My main requirement is that it must have high throughput and low latency, of which TiCDC has neither.
Conclusion
If it reads like the first 3 feature requests are minor paper-cuts compared to the last: I think that is a pretty fair assessment. I have spoken to many other TiDB users in North America, and they seem to be hitting these exact issues too. Some are experimenting with a workaround for minimum cost by offering multi-tenancy of the whole cluster, but there are drawbacks to that which make it not a good fit for my use case.
For DR: we are all moving from MySQL, where we are comfortable with async replication across regions. Deploying something similar in TiDB is challenging, and we are desperate for a solution.